Pada post kali ini, saya akan menggabungkan semua rangkuman materi Data Structure yang telah saya buat, selamat membaca.
Naufal Rifki Fauzan
2301890693
Kelas: CB01 - CL
Dosen: Ferdinand Ariandy Luwinda (D4522) & Henry Chong (D4460)
Naufal Rifki Fauzan
2301890693
Kelas: CB01 - CL
Dosen: Ferdinand Ariandy Luwinda (D4522) & Henry Chong (D4460)
Linked List
Sebelum saya masuk ke materi, saya akan menjelaskan tentang pengertian Linked List terlebih dahulu. Linked List adalah sebuah struktur data yang terdiri dari beberapa rangkaian catatan data, yang mana di setiap catatan terdapat referensi tentang catatan lainnya yang berada dalam urutan berikutnya dalam rangkaian.
Linked List bisa terbagi menjadi 3, yaitu:
- Circular Single Linked List
- Doubly Linked List
- Circular Doubly Linked List
Single Linked List
Sebelumnya kita akan membandingkan dulu linked list dengan array. Array adalah sekumpulan objek data serupa yang disimpan di lokasi memori berurutan di bawah judul umum atau nama variabel, array hanya bisa menyimpan satu jenis data. Sedangkan linked list adalah struktur data yang berisi urutan elemen di mana setiap elemen terkait dengan elemen berikutnya.
Di linked list kita bisa memakai fungsi alokasi memori yaitu malloc. Alasan mengapa kita harus memakai fungsi malloc ini adalah kita tidak selalu tahu berapa banyak objek dari jenis yang kita butuhkan, malloc juga akan membuat node di area heap memori dan mengembalikan pointer null. Berikut adalah contoh dari penggunaan malloc:



Demikian kumpulan dari semua rangkuman materi Data Structure saya.
struct List *node = (List *) malloc(sizeof(struct List));
-> Di sini malloc mengambil integer yang sesuai dengan jumlah byte yang dialokasikan pada heap,
kemudian mengembalikan null pointer yang menunjuk ke alamat byte yang dialokasikan.
Di dalam linked list, kita juga bisa melakukan insert dan delete. Insert adalah menambahkan suatu value baru ke dalam suatu linked list denagn cara mengalokasikan node baru secara dinamis dan menetapkan nilai untuk itu dan kemudian menghubungkannya dengan linked list yang ada, sedangkan delete adalah menghapus suatu nilai dalam linked list dengan cara mencari lokasi node yang menyimpan nilai yang ingin kita hapus.
 |
| Langkah-langkah insert |
 |
| Langkah-langkah delete |
Circular Single Linked List
Sebelum saya masuk ke Circular Single Linked List, saya akan menjelaskan terlebih dahulu tentang Singly Linked List. Singly Linked List adalah salah satu jenis linked list yang merupakan koleksi data elemen yang berbentuk linear yang mana juga disebut sebagai 'Nodes'. Elemen-elemen dari linked list ini bisa disimpan di lokasi memori yang berurutan ataupun tidak disimpan sama sekali. Pada linked list ini, pointer digunakan untuk mempertahankan urutan linear. Pada setiap nodes dibagi menjadi 2 bagian, bagian pertama yaitu 'INFO Field', bagian ini berisi info dari elemen-elemen linked list, lalu bagian kedua yaitu 'LINK Field' atau bisa disebut juga 'NEXT Pointer Field', bagian ini berisi alamat-alamat dari nodes selanjutnya.
Nah, Circular Single Linked List sebenarnya hampir sama dengan Singly Linked List, perbedannya hanya pada Circular Single Linked List, node terakhir akan menunjuk kembali ke node paling awal pada urutan.
Berikut adalah contoh dari Circular Single Linked List,

Pada gambar di atas kita bisa melihat bahwa, setiap node menunjuk ke node berikutnya dalam urutan tetapi node terakhir menunjuk ke simpul pertama dalam daftar. Elemen sebelumnya menyimpan alamat elemen berikutnya dan elemen terakhir menyimpan alamat elemen awal. Ini membentuk rantai melingkar karena elemen menunjuk satu sama lain secara melingkar. Kita bisa menyisipkan elemen di mana saja linked list ini, tetapi tidak dalam array karena berada dalam memori yang berdekatan.
Doubly Linked List
Doubly Linked List adalah urutan elemen di mana setiap simpul memiliki link ke simpul sebelumnya dan simpul berikutnya. Doubly Linked List terdiri da tiga bidang. Dalam hal ini, link dua node memungkinkan lintasan daftar di kedua arah tanpa perlu melintasi daftar untuk menemukan node sebelumnya. Kita dapat melintasi dari FISRT ke LAST serta LAST ke FIRST.
Pada linked list ini, setiap node terbagi menjadi 3 bagian;
- Bagian pertama adalah bagian PREV. Bagian ini adalah bidang pointer sebelumnya yang berisi alamat dari node yang ada sebelum node saat ini.
- Bagian kedua adalah bagian INFO. Bagian ini berisi informasi dari elemen.
- Bagian ketiga adalah bagian NEXT. Bagian ini adalah bidang pointer berikutnya yang berisi alamat dari node yang setelah node saat ini.
Berikut adalah contoh dari Doubly Linked List,

Ada dua pointer FIRST dan LAST, FISRT menunjuk ke node pertama dalam daftar, dan LAST menunjuk ke node terakhir dalam daftar. Bidang PREV dari node pertama dan bidang NEXT dari node terakhir berisi nilai NULL, ini menunjukkan akhir daftar di kedua sisi. Daftar ini dapat dilalui di kedua arah yang maju dan mundur.
Circular Doubly Linked List
Doubly Linked List adalah linked data structure yang terdiri dari sekumpulan catatan terkait berurutan yang disebut 'Nodes'. Doubly Linked List dapat digambarkan sebagai dua Singly Linked List yang dibentuk dari item data yang sama, tetapi dalam urutan berurutan yang berlawanan.
Berikut adalah contoh dari Circular Doubly Linked List,

Diagram di atas merupakan struktur dasar dari Circular Doubly linked List. Dalam Circular Doubly linked List, link sebelumnya dari node pertama menunjuk ke node terakhir dan link berikutnya dari node terakhir menunjuk ke node pertama.
Dalam Circular Doubly linked List, setiap node berisi dua bidang yang disebut link yang digunakan untuk mewakili referensi ke node sebelumnya dan berikutnya dalam urutan node.
Hashing Table
Ketika kita diberikan sejumlah data yang saling berelasi dalam jumlah yang besar, kita butuh sebuah data structure yang bisa dengan cepat mengakses data-data tersebut, seperti untuk insert, delete, dan search data. Hash table atau hashing table adalah metode data structure yang paling cepat dan efisien untuk memanipulasi sejumlah data yang besar. Hashing table sendiri adalah tipe data structure yang mana setiap entry di dalamnya didefinisikan sebagai semacam key yang nantinya akan digunakan untuk mempermudah searching ketika suatu data ingin dicari.
Di dalam hashing table mepunyai sebuah hash function. Hash function adalah sebuah fungsi yang ketika diterapkan pada suatu key pada hashing table akan menghasilkan suatu integer yang bisa digunakan sebagai address dari suatu hashing table. Hash function akan memetakan semua key ke dalam slot suatu array dan akan memberikan saran tentang indeks key mana yang harus disimpan dalam suatu array.
 |
| Contoh demonstrasi dari hashing table |
Binary Tree
Binary tree adalah tipe dari data strutur hierarkis yang mana pada setiap node memiliki maksimal hingga dua anak node, anak node ini biasa disebut sebagai node kanan dan node kiri. Setiap node pada binary tree mempunyai pointer untuk subtree kiri dan kanan, dan data element. Node yang terletak di paling atas tree disebut dengan root.
Binary tree biasa digunakan untuk mengimplementasikan binary search dan binary heap. Binary tree juga bisa digunakan untuk sorting data yang mana prosesnya dinamakan "heap sort".
 |
| Contoh dari binary tree |
Implementasi Hashing Table dalam Blockchain
Saya akan menjelaskan terlebih dahulu secara singkat tentang apa itu blockchain, Blockchain pada dasarnya adalah buku besar digital transaksi yang digandakan dan didistribusikan di seluruh jaringan sistem komputer di blockchain. Setiap blok dalam rantai berisi sejumlah transaksi, dan setiap kali transaksi baru terjadi di blockchain, catatan transaksi itu ditambahkan ke setiap buku besar peserta.
Teknologi blockchain memungkinkan informasi digital untuk didistribusikan, tetapi tidak disalin, sehingga setiap bagian data hanya dapat memiliki satu pemilik.
Implementasi hashing table pada teknologi blockchain sebenarnya tidak terlalu penting karena kebanyakan blockchain mendistribusikan semua data kepada semua orang, dan tidak perlu mencari rute atau tujuan.
Binary Search Tree
Saya akan membahas dulu apa itu binary search tree. Binary search tree adalah binary tree di mana setiap node comparable key (dan nilai yang terkait) dan memenuhi batasan bahwa key di setiap node lebih besar dari key di semua node di subtree kiri node itu dan lebih kecil dari key di semua node dalam subtree kanan node. Tujuan dari binary search tree ini adalah untuk maintain daftar angka yang sudah di sort.
Ada dua operasi dasar yang bisa kita lakukan dengan binary search tree, yakni:
1. Cek apakah sebuah nomor ada di binary search tree
Algoritma tergantung pada properti binary search tree bahwa jika setiap subtree kiri memiliki nilai di bawah root dan setiap subtree kanan memiliki nilai di atas root.
Jika nilainya di bawah root, kita dapat mengatakan dengan pasti bahwa nilainya tidak di subtree kanan; kita hanya perlu mencari di subtree kiri dan jika nilainya di atas root, kita dapat mengatakan dengan pasti bahwa nilainya tidak di subtree kiri; kita hanya perlu mencari di subtree kanan.
2. Memasukkan sebuah nilai ke dalam binary search tree
Memasukkan nilai pada posisi yang benar mirip dengan pencarian karena kami mencoba mempertahankan aturan bahwa subtree kiri lebih rendah daripada root dan subtree kanan lebih besar dari root.
Kita bisa terus menuju subtree kanan atau subtree kiri tergantung pada nilainya dan ketika kita mencapai titik subtree kiri atau kanan adalah nol, kita menempatkan simpul baru di sana.
Binary search tree mempunyai beberapa keuntungan ketika mengimplementasikannya, yaitu:
- Searching menjadi sangat cepat dengan binary search tree karena kita mendapatkan petunjuk di setiap langkah, tentang subtree mana yang mengandung elemen yang diinginkan.
- Binary search tree dianggap sebagai struktur data yang efisien dibandingkan dengan array dan linked list. Dalam proses pencarian, binary search tree menghapus setengah subtree di setiap langkah.
- Insertion dan deletion juga bisa dilakukan lebih cepat dengan binary search tree dibandingkan dengan array atau linked list.
AVL Tree
AVL tree adalah self-balancing binary search tree di mana setiap node mempertahankan informasi tambahan yang disebut balance factor yang nilainya -1, 0 atau +1. Nama AVL tree dibuat berdasarkan nama penemunya yakni Georgy Adelson-Velsky dan Landis.
Balance Factor
Balance factor dari sebuah node dalam AVL tree adalah perbedaan antara ketinggian subtree kiri dan subtree kanan node tersebut. Balance factor bisa dihitung dengan mengurangkan krtinggian subtree kiri dengan subtree kanan atau sebaliknya. Nilai dari balance factor harus selalu -1, 0, atau 1, jika sebuah tree tidak memenuhi persyaratan tersebut, maka tree tersebut bukan AVL tree.
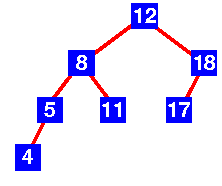 |
| Contoh dari AVL tree yang benar |
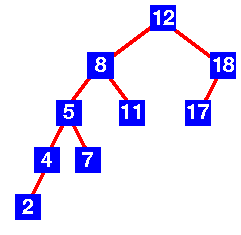 |
| Contoh dari AVL tree yang salah |
Insertion
Seperti RBT, insertion agak rumit dan melibatkan sejumlah kasus pada AVL tree. Implementasi insertion AVL tree banyak bergantung pada penambahan atribut tambahan, balance factor ke setiap node. Faktor ini menunjukkan apakah tree itu berat-kiri (ketinggian subtree kiri 1 lebih besar dari pada subtree kanan), seimbang (kedua subtree itu sama tinggi) atau berat-kanan (tinggi subtree kanan adalah 1 lebih besar dari subtree kiri). Jika keseimbangan akan dihancurkan dengan insertion, rotation akan dilakukan untuk memperbaiki keseimbangan.
Deletion
Deletion juga bisa dilakukan dengan cara yang sama seperti yang dilakukan di binary search tree. Deletion juga dapat mengganggu keseimbangan tree karena itu, berbagai jenis rotation bisa digunakan untuk menyeimbangkan tree.
Mengapa pakai AVL Tree?
AVL tree mengontrol ketinggian binary search tree dengan tidak membiarkannya miring/berat sebelah. Waktu yang diambil untuk semua operasi di binary search tree dengan tinggi h adalah O (h). Namun, dapat diperpanjang ke O (n) jika BST menjadi miring. Dengan membatasi ketinggian ini untuk log n, AVL tree memaksakan batas atas pada setiap operasi menjadi O (log n) di mana n adalah jumlah node.
Heap
Heap adalah data structure berbasis binary tree yang diimplementasikan menggunakan array, yang mana array adalah kumpulan elemen yang disimpan di lokasi memori yang berdekatan dengan ide untuk menyimpan beberapa item dari jenis yang sama bersamaan.
Ada beberapa jenis dari heap, yakni:
- Min-heap
Nilai setiap node lebih besar dari atau sama dengan nilai induknya, dengan nilai minimum pada node akar.
 |
| Contoh dari min-heap |
- Max-heap
Nilai setiap node kurang dari atau sama dengan nilai induknya, dengan nilai maksimum pada node akar.
 |
| Contoh dari max-heap |
Terdapat syarat-syarat struktural dari heap, yaitu:
- Semua level heap harus penuh, kecuali yang terakhir
- Node harus diisi dari kiri ke kanan.
- Nilai-nilai di child kanan dan kiri atau node tidak berpengaruh apa-apa.
Terdapat juga operasi-operasi yang bisa dilakukan pada heap, yaitu:
- Find -> mencari item pada heap
- Insert -> menambahkan item di heap dan memastikan properti heap dipertahankan min-heap dan max-heap property
- Delete -> menghapus item pada heap
- Extract -> mengembalikan nilai suatu item lalu menghapusnya dari heap.
- Replace -> extract atau pop root dan memasukkan atau mendorong item baru di heap dan memastikan properti heap telah mempertahankan min-heap dan max-heap property.
Dalam mengimplementasikan heap tentu akan ada keuntungan dan kerugiannya. Keuntungan dalam menggunakan heap yakni:
- Dapat mengakses item terkecil dengan cepat. Heap memungkinkan kita untuk mengambil item terkecil (root) dalam O (1) O (1) waktu, sambil menjaga operasi lain relatif ringan.
- Heap juga biasanya diimplementasikan dengan array, menghemat overhead dari menyimpan pointer ke node anak.
Sedangkan kerugian dalam penggunaan heap yaitu:
- Heap hanya menyediakan akses mudah ke item terkecil. Menemukan item yang lainnya di heap membutuhkan O (n) O (n) waktu, karena kita harus beralih melalui semua node.
Tries
Tries adalah data structure tree terurut yang digunakan untuk menyimpan array asosiatif.
Ciri-ciri dari tries yakni:
- Setiap vertex mewakili satu kata atau awalan.
- Root mewakili karakter kosong (‘’).
- Sebuah vertex yang merupakan tepi k jarak dari root memiliki awalan terkait panjang k.
Layaknya heap, tries juga mempunyai kelebihan dan kekurangan. Kelebihan dari penggunaan tries adalah:
- Terkadang tries bisa menjadi pilihan yang hemat. Jika kita menyimpan banyak kata yang dimulai dengan pola yang sama, percobaan dapat mengurangi biaya penyimpanan keseluruhan dengan menyimpan awalan bersama satu kali.
- Efisien pada query prefix. Tries dapat dengan cepat menjawab pertanyaan tentang kata-kata dengan awalan yang sama.
Sedangkan kekurangan dari tries yakni:
- Tries lebih jarang menghemat ruang jika dibandingkan dengan menyimpan string dalam satu set.
- Sebagian besar bahasa tidak dilengkapi dengan implementasi built-in trie sehingga harus menerapkannya sendiri.
Demikian kumpulan dari semua rangkuman materi Data Structure saya.
Comments
Post a Comment